Batch Processing
Batch Processing is a way of processing records in batch or in collections. The major advantage of batch job is they execute in parallel and hence provide maximum throughput.
Batch jobs are ideal for doing following
- Sync two system in real time e.g. account update details from ERP to Salesforce
- ETL tool – processing files or DB records to any other systems
- Processing bulk data
Overview
Batch jobs work on incoming payload by breaking them in individual records and processing each record asynchronously. It saves the individual records in persistence store. This will provide the required reliability to Batch processing, as in case of application crash it will resume from the same point where it stopped.

How it works in Mule 4
If we drag and drop Batch job activity in Mule 4 then it will automatically create a flow for the batch job. So batch job always expect a payload from the flow’s source section or from the calling flow
First look into the configuration
Batch Job Configuration

To understand these properties better we can think of a scenario say –
If 1000 records are coming to batch processing then Mule runtime will create the Batch job instances based on provide Batch Block Size e.g. 10 (batch job instances) * 100 (block size) = 1000 records. Each Batch job instance will be processed in the provided Scheduling Strategy.
Below are the configuration details we can define for Batch job
- Name – Batch job name
- Max Failed Records – this value define on how many failed records we should stop the Batch job processing. By default 0 means if any record fail then it will stop the batch job execution. -1 means not to stop even if all the incoming payload fails
- Scheduling Strategy – Batch jobs execution
- ORDERED_SQUENTIAL (the default): If several job instances are in an executable state at the same time, the instances execute one at a time based on their creation timestamp.
- ROUND_ROBIN: This setting attempts to execute all available instances of a batch job using a round-robin algorithm to assign the available resources.
- Job instance id – given or provided to each batch job created for batch processing
- Batch Block Size – default 100 – Block size define the number of records given to each thread for execution. Bigger the number less I/O operation will be performed by the thread but need more memory to hold block. So always match the block size w.r.t to vCore size (thread count) and input payload. This directly effect the performance of the batch job processing
- Max Concurrency – Defining the number of threads which can participate in batch processing if you don’t want the default thread count which depends on vCore size of the machine
- Target – to save the Batch stats result
Once done with the configuration we can see two sections in Batch Job – Process Records and On Complete

Process Records – Process records can have multiple batch steps
Batch Steps – Each batch steps can contain related processor to work on individual records for any type of processing like enrichment, transformation or routing. This will help in segregating the processing logic
We can enhance the Batch Step processing by providing the filter criteria to limit the processing to eligible records only

We can see two options
Accept Expression – expression which hold true for the processing records e.g. #[payload.age > 27]
Accept Policy – can hold only below predefined values
-
-
- NO_FAILURES (Default) – Batch step processes only those records that succeeded to process in all preceding steps.
- ONLY_FAILURES – Batch step processes only those records that failed to process in a preceding batch step.
- ALL – Batch step processes all records, regardless of whether they failed to process in a preceding batch step.
-
Batch Step can contain zero or max one Batch Aggregator
Batch Aggregator – As the name suggest can execute related processor on bulk records to increase the performance. In today’s time most of the target system e.g. Salesforce, Database, REST call accept collection of records for processing and sending individual records to target system can become a performance bottleneck so Batch Aggregator help by send bulk data to target system.
Size for Batch aggregator can be defined as below (both are mutually exclusive)
Aggregator size – Processing a fixed amount of records e.g. 100 records
Streaming – All records
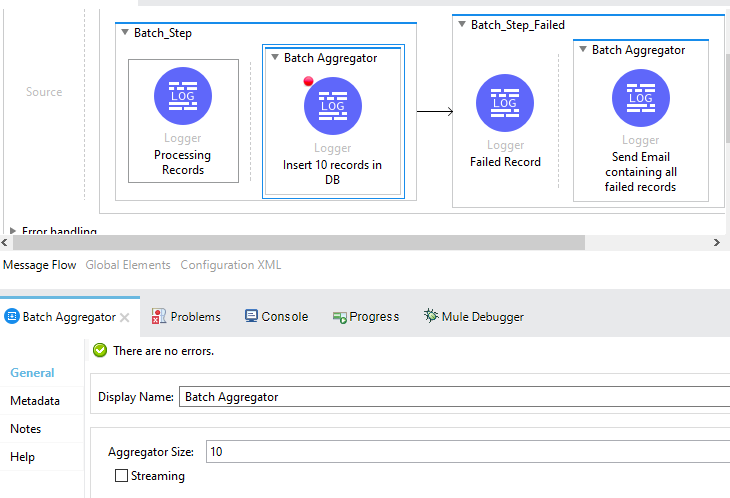
On Complete – this section is optional and only execute in end e.g. when batch steps are executed for all the incoming records. This is mostly used to provide insight of batch processing e.g. Total record processed, failed, successfully processed etc. In this phase MuleSoft update the payload with batch job stat values.
Within Mule Runtime (In Memory)
Batch job contain 3 different phases
Load and Dispatch (Phase) – Implicit Phase – Mule runtime do the initial setup to run the batch job processing. This phase create batch job instances and persistence queue.
- Mule splits the message using Dataweave. This first step creates a new batch job instance. Mule exposes the batch job instance ID through the batchJobInstanceId variable. This variable is available in every step and the on-complete phase.
- Mule creates a persistent queue and associates it with the new batch job instance.
- For each item generated by the splitter, Mule creates a record and stores it in the queue. This activity is “all or nothing” – Mule either successfully generates and queues a record for every item, or the whole message fails during this phase.
- Mule presents the batch job instance, with all its queued-up records, to the first batch step for processing.
Process (Phase) – Actual processing start in this phase where all the records in a batch job instances are processed asynchronously. Each record is picked from the queue by batch step and processors within the batch step are executed on the record. Once batch step processing complete then record is again send back to the Queue where it’s picked by the next Batch Step
Records keep the track of their execution and are persisted in Queues. If any record failed then it’s marked as failed record so that it will be not picked by any other batch steps
Once all records are processed then that batch job instance is marked as processed
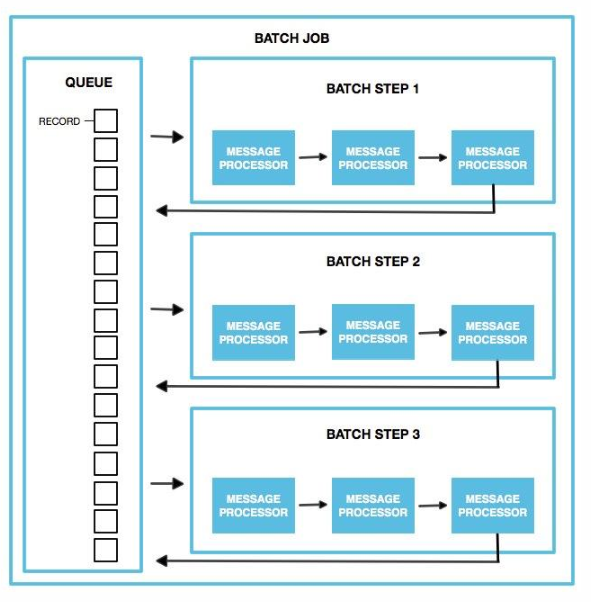
On Complete (Phase) – This is optional phase and execute in last when all the records are processed. This phase can provide the insight stats for the batch processing where we can log or process (reporting, emailing) the stats.
if we convert the Stats payload to JSON
{
"onCompletePhaseException":null,
"loadingPhaseException":null,
"totalRecords":9,
"elapsedTimeInMillis":1229,
"failedOnCompletePhase":false,
"failedRecords":1,
"loadedRecords":9,
"failedOnInputPhase":false,
"successfulRecords":8,
"inputPhaseException":null,
"processedRecords":9,
"failedOnLoadingPhase":false,
"batchJobInstanceId":"2efa3c10-a62a-11ea-8a1a-9aaf65ed66d8"
}
Knowledge bites
Batch job is widely used for parallel processing of records but this is not the only activity to achieve parallel execution in MuleSoft. There are other activities like Scatter-Gather, Async and For-Each Parallel are present but they have their own use cases.
Thanks for the explanation !
Could you also throw some light on Integration Patterns with some use cases .
Thanks Anand for the Suggestion!
We are writing POST on Integration patterns now 🙂
https://mulesy.com/category/mulesoft-integration-patterns/
Nice explanation. Can you please clarify my doubt on batch processing.
Q) I have a scheduler and it will trigger every 5 min but unfortunately first scheduled has taken long time (1hr) to complete the job and configure the maxconcurrency as 1. What will happen about other schedules?
If back-pressure is triggered because no resources are available at the time of the trigger, that trigger is skipped.
More on back-pressure
Thanks,
Mulesy Team
Thank you so much for your reply.
Thanks, it helped me a lot 🙂
Hi,
I’ve mule applications where the data is extracted and posted into different sources using a batch job. These mule applications have different endpoints, whenever I call any one of the endpoints in postman, the response body is some weird characters contains java.ArrayList etc., we can avoid this by setting transform message after batch job. But I need to send the loaded, successful, and failed records as a response where we can get only if the batch job is completed. Is there a way to wait until the batch job is completed then I send the batch payload response?
thanks for this
i want mulesoft all topic wise explation pdf